Consistent Hashing
So, you're building an application. As it grows, your single database server can't keep up with the incoming reads and writes. You try the usual scaling techniques:
- Read replicas to offload heavy read traffic.
- Partitioning within a single node when tables get too large.
But if even one machine can't handle the storage or write load, you eventually need to shard - distribute partitions across multiple servers.
And that's where a new problem appears, how do you decide which node should hold which data?
The simple solution is to use a hash function and the modulo operator:
node_index = hash("user_123") % 4;The hash() function turns the key into a big number, and % 4
maps it to one of 4 nodes (0-3). The data is nicely distributed.
The Problem
Your application starts getting more traction. Four database nodes aren't enough. You need to scale up to five to handle the load.
You change your formula to % 5.
And that is a massive problem.
The result of hash("user_123") % 4 is almost certainly different from hash("user_123") % 5.
So all the keys suddenly point to different nodes.
This creates the need for a huge data migration process. You might have to take your system offline while terabytes of data are copied between servers. The risks are high.
Consistent Hashing
Consistent hashing is a clever idea that minimizes the amount of data that needs to be moved when the number of nodes changes.
Instead of a line, imagine all the possible hash values on a circular ring.
-
Place Nodes onto the ring: First, you take each of your database nodes (A, B, and C) and use a hash function on their names or IP addresses. This gives each node a unique position on the ring. For example, Node A might land at 3 o'clock, Node B at 7 o'clock, and Node C at 11 o'clock.
-
Place Data on the Ring: When a new piece of data comes (e.g., "user_123"), you hash its key and find its position on the ring.
-
Find its Node: To find its node, you move clockwise around the ring until you find the first node.
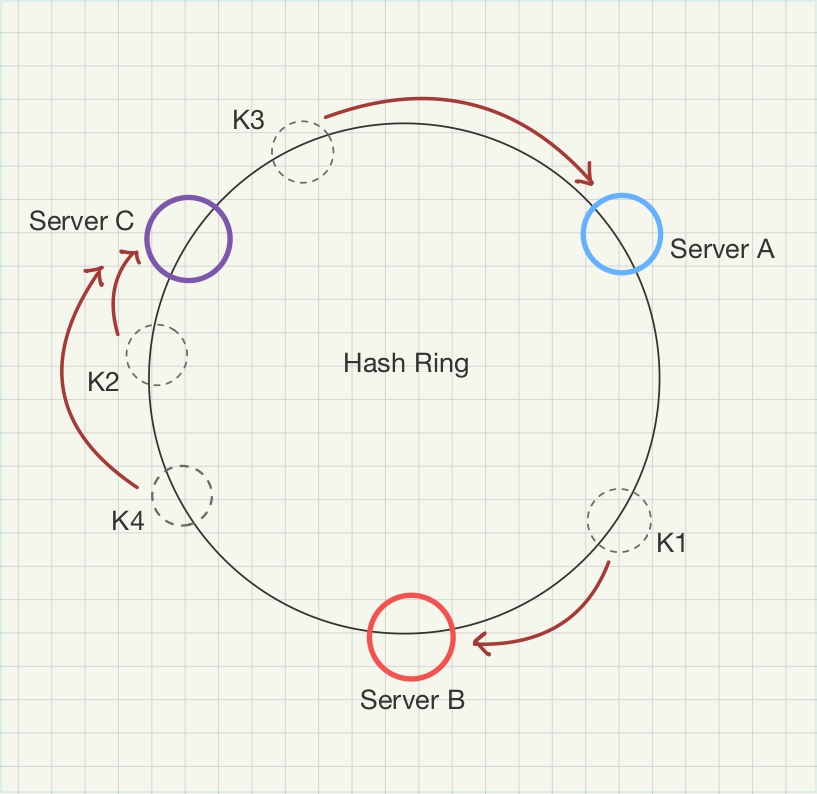
In our example, let's say "user_123" landed at 5 o'clock and moving clockwise, the first node we get is Node B at 7 o'clock. Therefore, Node B is responsible for "user_123". If a key landed at 12 o'clock, it would belong to Node A (at 3 o'clock).
What happens when we add a new node?
Let's say we add Node D, and it hashes to the 9 o'clock position. It just slots right onto the ring. What data needs to be moved? Only the data that falls between 7 o'clock (Node B) and 9 o'clock (the new Node D). These records, which used to belong to Node C, are now moved to D. The data on Node A and Node B doesn't move at all. Saving us from the huge migration process.
What happens when we remove a node?
If Node A at 3 o'clock suddenly goes offline, it's removed from the ring. Now, any data that was mapped to it (the keys between 11 o'clock and 3 o'clock) simply continues its clockwise journey and gets remapped to the next available node, B. Again, only the data from the failed node needs to be redistributed.
Avoiding Hotspots using Virtual Nodes
The basic system is great but it could be better. What if, by random chance, your nodes all hash to positions that are clumped together on one side of the ring?
Node A -> 1 o'clock
Node B -> 2 o'clock
Node C -> 3 o'clockHere, Node A would be responsible for storing a huge range of data from 3 o'clock all the way around to 1 o'clock, while Nodes B and C would store very little. The imbalance creates a "hotspot", overwhelming one node while others are idle.
We use Virtual Nodes to solve this issue.
Instead of putting one "Node A" on the ring, we create multiple virtual representations of it, like "Node A-1", "Node A-2", and "Node A-3". Each of these virtual nodes is hashed separately and placed at different points on the ring, but all of them map back to the same physical Node A.
Benefits:
-
Better distribution: With many points on the ring for each node, the data is spread out much more evenly. The chance of a "hotspot" is reduced.
-
Smoother Failures: If Node A goes down, its ten virtual nodes disappear from the ring. The small amount of data each one managed is then picked up by ten different virtual nodes. This spreads the load of a failure instead of dumping it all onto a single neighbor.
Where it's used
Consistent hashing is everywhere in modern distributed systems:
- NoSQL Databases like DynamoDB, Cassandra, and Riak use it to partition data across a cluster of nodes.
- Distributed Caches like Memcached and Redis clusters use it for the exact same reasons.
- Storage systems: Any system that needs to spread huge amounts of data across many machines, like a CDN or object storage, likely uses this principle.